Chapter 6 Partition&Pool Algorithms
innovation("Partition&Pool","T*","Recursive partition and pool paradigm")
dependency("Partition&Pool","Divide&Conquer")
innovation("Wing-partitioning","B*","Stable partitioning without counting")
dependency("Wing-partitioning","Partition&Pool")
dependency("Wing-partitioning","Symmetric-sorting")
innovation("Kiwisort","A","Stable Partition&Pool sort 100% buffer")
dependency("Kiwisort","Wing-partitioning")
innovation("Buffer-partitioning","B*","partitioning data and buffer")
dependency("Buffer-partitioning","Partition&Pool")
dependency("Buffer-partitioning","Ordinal-machine")
innovation("Symmetric-partitioning","B*","symmetric partitioning data and buffer")
dependency("Symmetric-partitioning","Wing-partitioning")
dependency("Symmetric-partitioning","Buffer-partitioning")
dependency("Symmetric-partitioning","FLIP")
dependency("Symmetric-partitioning","DIET")
innovation("Gapped-wrapup","B*","collecting the gapped results")
dependency("Gapped-wrapup","Symmetric-partitioning")
innovation("Swansort","A","distance-reducing stable P&P sort 100% buffer")
dependency("Swansort","Gapped-wrapup")
dependency("Swansort","Symmetric-partitioning")
innovation("Storksort","A","distance-reducing stable P&P sort 50% buffer")
dependency("Storksort","Symmetric-partitioning")
dependency("Storksort","Footprint")For generic sorting with \(\mathcal{O}(N \log{n})\) worse case, Split&Merge algorithms need not more than one pass over the data per recursion level. Partition&Pool usually need more passes. One reason is that determining a median for balanced partitioning is costly, even when using an approximate median of medians as in the BFPRT-select algorithm of Blum et al. (1973). Using one (or more) random pivots avoids these costs, the price for this is a missing \(\mathcal{O}(N \log{n})\) worse case guarantee. Another reason for multiple passes in generic stable partitioning with 100% buffer is that two passes are needed, one for determining the size of the partitions and one for actually distributing the elements to the partitions in a stable manner. Quicksort avoids the need to know the beginning of the second partition by writing the second partition in reverse direction beginning with the outer right position. Partition&Pool is doubly clever by also avoiding the need for buffer, and the price for this is missing stability and missing generality (SWAPS require equal size of elements).
Writing two partitions from the left and right outer ends is also possible with 100% buffer, this allows size-varying elements but is still not stable. However, under the greeNsort® definition of Symmetric-sorting it is possible to make this stable by tracking the number of direction reversals. Once the recursion reaches a (completely tied) leaf, stability can be achieved by reversing the order of ties if and only if the number of reversals was odd. This method I call Wing-partitioning. The resulting sort when using 100% separate buffer memory (like in Knuthsort) and the B-level innovation – (F)ast (L)oops (I)n (P)artitioning (FLIP) and B-level innovation – (D)istinct (I)dentification for (E)arly (T)ermination (DIET) methods I call Kiwisort. Kiwisort features early termination on ties and a \(\mathcal{O}(N \log{n})\) probabilistic worse case, like Z:cksort.
The section on Symmetric-merging was already written to also cover Symmetric-partitioning. Instead of a separate buffer region, it is possible to also use contiguous data-buffer-memory and do Partition&Pool of data and 100% buffer. The two partitions are written in-place, one from the read direction (e.g. from left) and the other from the opposite direction (e.g. from right). This creates two partitions with 100% buffer in between, which can be partitioned recursively. Once the data is fully partitioned at the leafs of the recursion tree, there are gaps of buffer between the data. Hence a final pass over the data is needed to collect the data into contiguous memory, this method I call Gapped-wrapup. The resulting sort I call Swansort. Note that the in-situ implementation measured here requires a deterministic median split at the top level in order to properly distribute 50% of the data to the 100% freshly allocated temporary memory, this makes the in-situ implementation somewhat slower than the ex-situ implementation.
It is possible to modify Swansort to run with only 50% buffer. How? By re-introducing a counting pass! In the counting pass the algorithm determines the sizes of the two partitions. Once the partition size is known, the bigger partition is written in-place in the read-direction, the smaller partition is written from the opposite side. Since the smaller partition is \(\le\) 50% it will always fit into the 50% buffer. The result looks similar to Swansort with buffer between two partitions, and can be easily partitioned recursively. Once the data is fully partitioned at the leafs of the recursion tree, there are not only gaps of buffer between the data, the sorted pieces are also not in sorting order. But each leaf of the recursion tree knows to which position in sorted order its data belongs and can send it to there. Writing the data directly into some result memory is not an attractive option, because the required existence of this memory would actually turn this 150% memory algorithm to a 250% memory algorithm. However, the algorithm could send the data over a wire. There are two options how to do this. 1) in a serial execution, the data could simply be sent in serial order. 2) in a parallel execution, the data could be sent together with its designated position. The resulting algorithm I call Storksort. Storksort could make sense as a cloud-sorting service which receives data and sends it back sorted.
In conclusion: for sustainable stable binary sorting in contiguous memory, Partition&Pool is a less efficient paradigm than Split&Merge, with the important exception of early termination on ties. Partition&Pool is much more efficient, if one gives up the simplicity of binary sorting for k-ary sorting (which can better amortize the high cost per level) and/or the locality of contiguous memory for block-managed memory (which allows to skip a counting-pass). The (I)n-place (P)arallel (S)uper (S)calar (S)ample(So)rt (IPS4o) in block-managed-memory with \(\sqrt{N}\) buffer by Axtmann et al. (2017) is an excellent k-ary algorithm, it has the following pros and cons:
- it has high implementation complexity
- it is not stable
- it requires random block-access
- it cannot sort variable size (except for indirect sorting which requires random access)
- the serial version is less more efficient than Pdqsort and Ducksort
- the parallel version is more efficient than Pdqsort, Ducksort
- IS4o is adaptive to presorted (and reverse-sorted), but IPS4o is much less adaptive
It would be interesting
- to see if IPS4o could benefit from Z:cksort’s FLIP method
- to stabilize IPS4o under the definition of Symmetric-sorting using greeNsort® methods
- to see if IPS4o could benefit from the \(\sqrt{N}\) block management of Walksort and Jumpsort
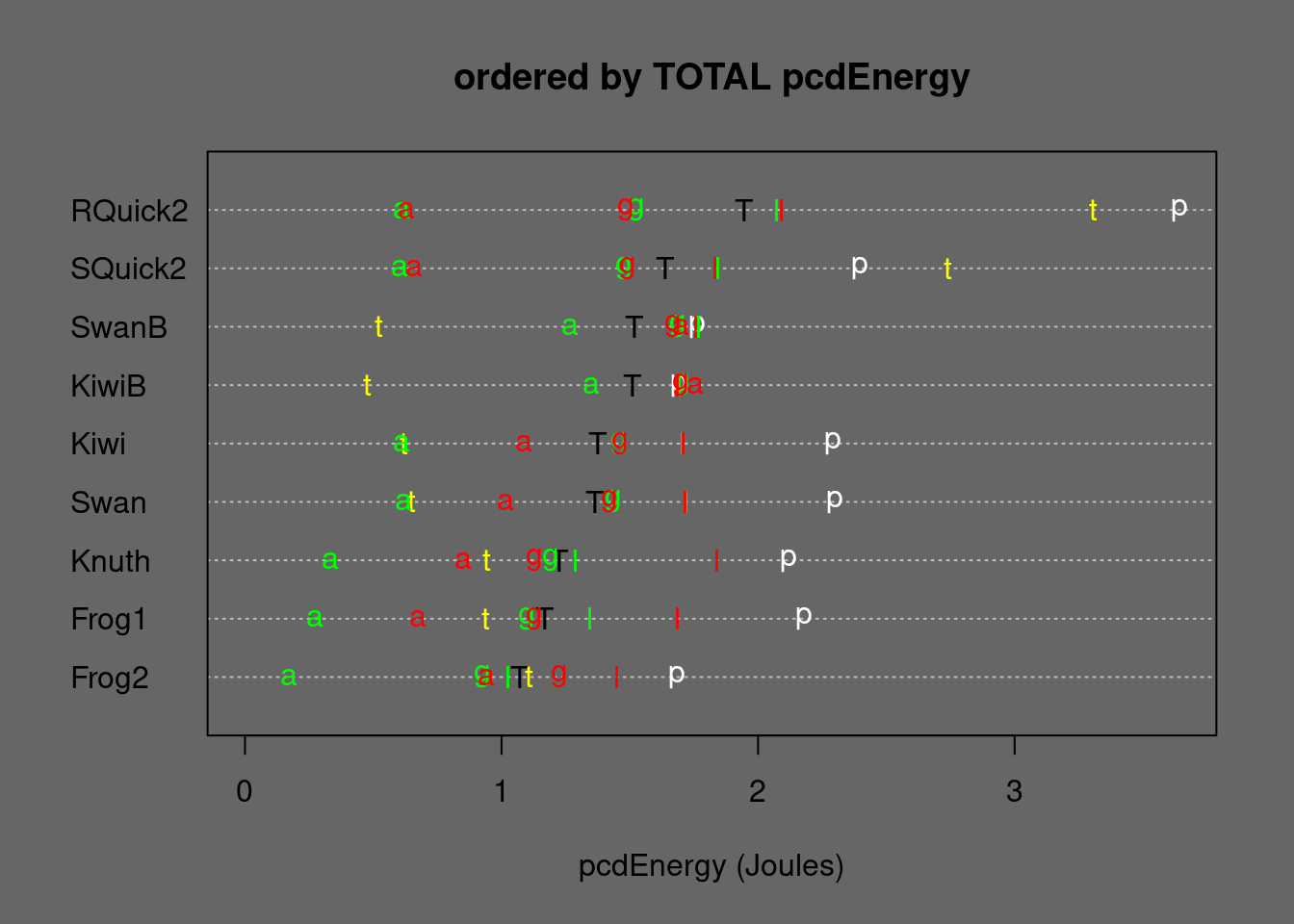
Figure 6.1: Medians of stable partitioning alternatives ordered by TOTAL Energy. T=TOTAL, p=permut, t=tielog2; green: a=ascall, g=ascglobal, l=asclocal; red: a=descall, g=descglobal, l=desclocal
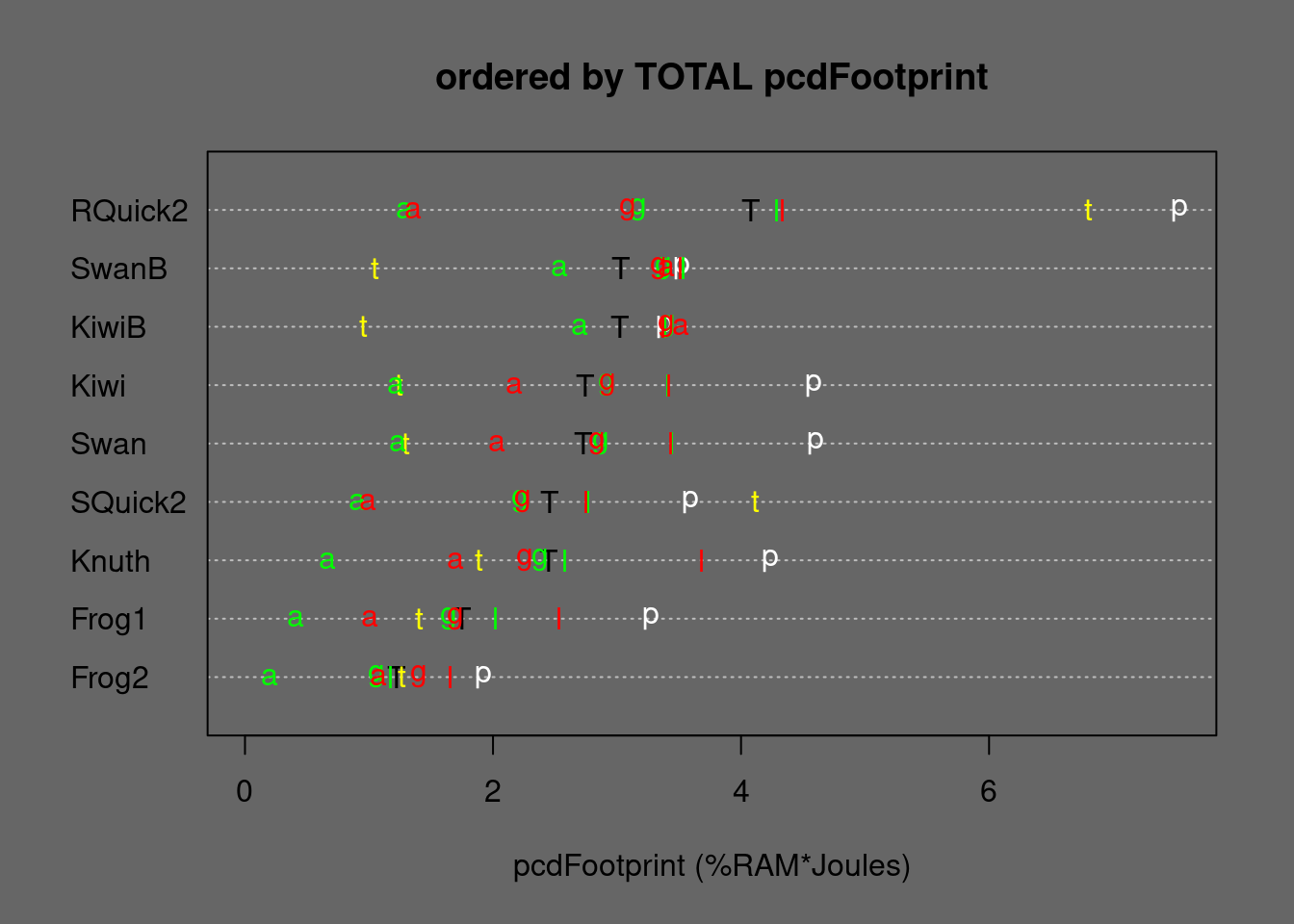
Figure 6.2: Medians of stable partitioning alternatives ordered by TOTAL Energy. T=TOTAL, p=permut, t=tielog2; green: a=ascall, g=ascglobal, l=asclocal; red: a=descall, g=descglobal, l=desclocal
| r(%M) | r(rT) | r(pcdE) | r(pcdF) | d(pcdE) | p(rT) | p(pcdE) | p(pcdF) | |
|---|---|---|---|---|---|---|---|---|
| TOTAL | 1 | 1.10 | 1.12 | 1.12 | 0.14 | 0 | 0 | 0 |
| ascall | 1 | 1.85 | 1.85 | 1.85 | 0.28 | 0 | 0 | 0 |
| descall | 1 | 1.15 | 1.19 | 1.19 | 0.16 | 0 | 0 | 0 |
| ascglobal | 1 | 1.20 | 1.21 | 1.21 | 0.25 | 0 | 0 | 0 |
| descglobal | 1 | 1.23 | 1.26 | 1.26 | 0.29 | 0 | 0 | 0 |
| asclocal | 1 | 1.35 | 1.33 | 1.33 | 0.43 | 0 | 0 | 0 |
| desclocal | 1 | 0.94 | 0.93 | 0.93 | -0.12 | 0 | 0 | 0 |
| tielog2 | 1 | 0.66 | 0.69 | 0.69 | -0.29 | 0 | 0 | 0 |
| permut | 1 | 1.07 | 1.09 | 1.09 | 0.18 | 0 | 0 | 0 |
To illustrate the height of the greeNsort® partition&pool inventions, I show the innovation-lineage of Storksort: all innovations on which Storksort depends form a (D)irected (A)cyclic (G)raph (DAG):
Figure 6.3: Innovation-lineage of Storksort